
Sponsor:
- DoD Modernization Program
Project Team Members:
Northwestern University
- Prof. Alok Choudhary
- Prof. Wei-keng Liao
Syracuse University
- Prof. Donald Weiner
- Prof. Pramod Varshney
Air Force Research Labs
- Dr. Richard Linerman
- Dr. Mark Linerman
Parallel Pipeline Computation Model
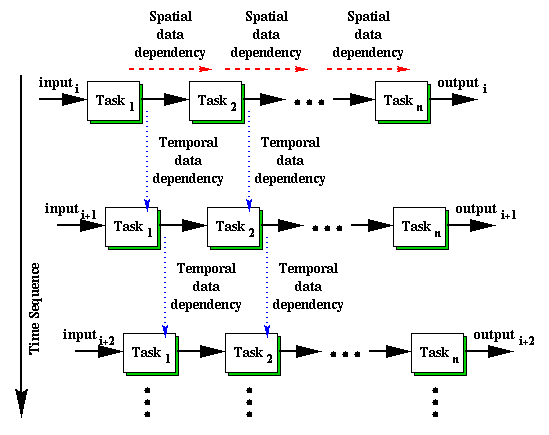
The system model for the type of STAP applications considered in this work is shown in Figure 1. This model is suitable for the computational characteristics found in these applications. A pipeline is a collection of tasks which are executed sequentially. The input to the first task is obtained normally from sensors or other input devices and the inputs to the rest of the tasks in the pipeline are the outputs of their previous tasks. The set of pipelines shown in the figure indicates that the same pipeline is repeated on subsequent input data sets. Each block in a pipeline represents one parallel task, which itself is parallelized on multiple (different number of) compute nodes.
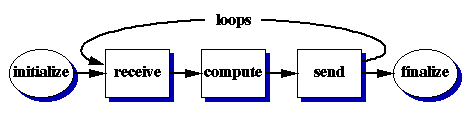
From a single task point of view, the execution flow consists of three phases: receive, compute, and send phases, shown in Figure 1 In the receive and send phases, communication involves data transfer between two different groups of compute nodes. It also involves message packing in the send phase and unpacking in the receive phase. Data redistribution strategy plays an important role in determining the communication performance. In the compute phase, work load is evenly partitioned among all compute nodes assigned in each task to achieve the maximum efficiency. For the parallel systems with multiple processors in each compute node, multi-threading technique can be employed to further improve the computation performance. We will discuss the implementation of multiple threads in our parallel pipeline system later in this paper.
Data dependency:
In such a parallel pipeline system, there exist both spatial and temporal parallelism that result in two types of data dependencies and flows, namely, spatial data dependency and temporal data dependency [1, 2]. Spatial data dependency can be classified into inter-task data dependency and intra-task data dependency. Intra-task data dependencies arise when a set of subtasks needs to exchange intermediate results during the execution of a parallel task in a pipeline. Inter-task data dependency is due to the transfer and reorganization of data passed onto the next parallel task in the pipeline. Temporal data dependency occurs when some form of output generated by the tasks executed on the previous data set are needed by tasks executing the current data set.
Reference:
- A. Choudhary, "Parallel Architectures and Parallel Algorithms for Integrated Vision Systems", Kluwer Academic Publishers, Boston, MA, 1990.
- A. Choudhary and R. Ponnusamy, "Run-Time Data Decomposition for Parallel Implementation of IMage Processing and Computer Vision Tasks", Journal of Concurrency, Practice and Experience, 1992.
Click here to go back