
Sponsor:
National Science Foundation, award number OCI-0724599Project Team Members:
Northwestern University
Argonne National Laboratory



NSF SDCI: Scalable I/O Optimizations for Peta-scale Systems

Figure 1. shows (i) A typical I/O software stack (layers) shown in blue background (ii) Each layer's typical role (not an exhaustive list), and (iii) The focus of this project, which is shown in red color.
We develop optimizations and tools to improve and enhance these software layers by
considering a holistic view and interaction complexities amongst the layers.
The MPI-IO component of the MPI-2 message passing interface standard has become
the de-facto low-level parallel I/O interface. MPI-IO provides all the
capabilities necessary for high-performance file I/O in ultrascale systems,
including support for noncontiguous I/O in memory and file, asynchronous I/O,
collective I/O, and control over consistency semantics. We propose mechanisms
that allow different software layers to interact and cooperate with each other
to achieve end-to-end performance objectives. Our work for designing scalable
approaches across I/O stack comprises of the following main topics:
- PnetCDF software optimizations
- Adaptive File Domain Partitioning Methods for MPI Collective I/O
- I/O Delegation
PnetCDF software optimizations:
Parallel netCDF provides two sets of APIs, (i) the original API provided by the netCDF,
and, (ii) an enhanced API so that a user can easily migrate to
higher-performance parallel library for I/O. There was no parallel interface to
netCDF files available prior to this work. The new parallel API closely mimics
the original API, but is designed with scalability in mind and is implemented
on top of MPI-IO. Our goal in this part of the project is to improve Parallel
netCDF and provide performance optimizations for achieving scalability that
would be needed on Petascale systems. Details about PnetCDF project can be
found here.
Adaptive
File Domain Partitioning Methods for MPI Collective I/O:
File domain is a term used by ROMIO implementation. Adopting the two-phase
I/O strategy, ROMIO divides the aggregate access file region of a collective
I/O evenly among a set of I/O processes into disjoint segments, named file
domains. The I/O processes, or I/O aggregators,
are a subset of the MPI processes that act as I/O proxies for the rest of the
processes. In the communication phase, all processes redistribute their I/O
data to the aggregators based on the ranges of file domains. In the I/O phase,
aggregators make read/write requests for the assigned domains to the file
system. Being able to combine many small non-contiguous requests, the two-phase
I/O strategy has been demonstrated to be very successful, as most of the file
systems handle large contiguous requests more efficiently. However, the even
partitioning method does not necessarily bring out a file system's best
performance.
We propose a set of file domain partitioning methods that aim to minimize the file system control overhead, particularly the file locking cost. Since different file systems have different file locking implementations, we have designed these methods that are most suitable and adaptable for the parallel file systems. Our task starts with a few file domain partitioning methods: stripe-aligned, stripe-size I/O, static-cyclic, group-cyclic, and transpose methods. We focus on the analysis of lock conflicts and acquisition costs for each of these methods, particularly for very large-scale parallel I/O operations. The stripe-aligned method aligns the file domain partitioning with file system's stripe boundaries, as illustrated in Figure 2(a). The lock granularity of a file system is the smallest size of file region a lock can protect. For most of the parallel file systems, such as GPFS and Lustre, it is set to the file stripe size. If file domains are not partitioned at the file stripe boundaries, lock contentions will occur. In addition, client-side cache-page false sharing will occur on the stripes that partially belong to two file domains. False sharing is when a file stripe cached by a client must be flushed immediately, because the same stripe is simultaneously requested by a different client. The stripe-aligned method can avoid lock contentions by aligning the file domain partitioning to lock boundaries.
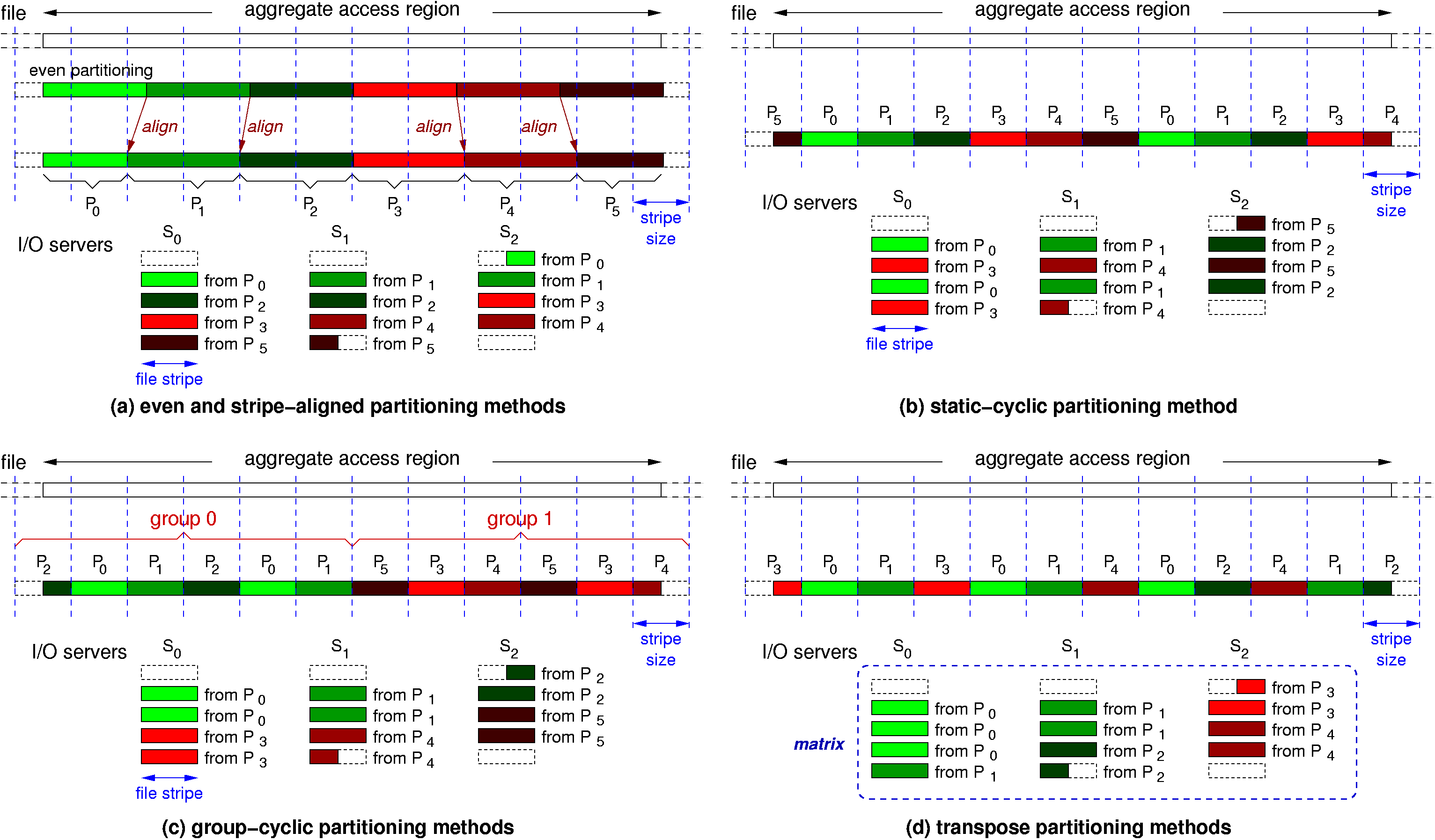
Figure 2. Four file domain partitioning methods for MPI
The stripe-size I/O method is based on the stripe-aligned method but carries out the I/O
request one stripe at a time. This method aims to reduce the lock requisition
cost by reducing the system overhead for enforcing I/O atomicity. To guarantee
I/O atomicity, file systems wrap a lock/unlock around each individual
read/write call. For large requests covering more than one stripe, a process
must obtain locks for those stripes prior to accessing any of them. If the
underlying file system adopts the server-managed locking protocol, such as
Lustre, a single I/O request can result in multiple lock requests, one for each
stripe to the server where the stripe is stored. This stripe-size I/O method
carries out the I/O one stripe at a time, so the I/O to a stripe can start as
soon as its lock is granted. For large I/O requests, it expedites the I/O by
saving the time of waiting for multiple locks to be granted.
The static-cyclic
method persistently assigns all stripes of a file to the I/O aggregators in
a round-robin fashion. Usually file domains must be re-calculated in each
collective I/O, as the aggregate access region may change from one collective
I/O to another. In this method, the association of file stripes to I/O
aggregators does not change. This method has the following properties. When the
number of aggregators is a multiple of the number of I/O servers, the I/O
requests from an aggregator will always go to the same I/O server. As shown in
Figure 2(b), aggregator P0's file domain covers the stripes that belong to
server S0 only. When the number of aggregators is a factor of the number of I/O
servers, each aggregator's file domain consists of stripes belonging to a
subset of servers and those servers only. In other words, each I/O server will
receive requests from one and only aggregator. If persistent communication
channels can be established between the compute nodes and I/O servers, this
method can further reduce the network cost across multiple collective I/Os.
As
can be seen in Figure 2(b), file stripes from one aggregator's file domain
produced by the static-cyclic method are interleaved with another aggregator's
at every I/O server. For instance, at server S0, stripes from aggregator P0 are
interleaved with the ones from P3. Under the server-managed extent-based
locking protocol, such an interleaved access pattern will cause lock requests
revoking each other's lock extent held by the interleaved aggregators. To avoid
such an interleaved access, the group-cyclic method is proposed. It
first divides the I/O aggregators into groups, each of size equal to the number
of I/O servers. The aggregate access region of a collective I/O is also divided
into sub-regions, each assigned to an aggregator group. Within each sub-region,
the static-cyclic partitioning method is used to construct the file domains for
the aggregators in the group.
Figure 2(c) illustrates the group-cyclic partitioning method. The group-cyclic method can minimize lock extent conflicts only when the number of aggregators is either a factor or a multiple of the number of I/O servers. This property breaks if the numbers of aggregators and I/O servers are not perfectly aligned. We propose the transpose partitioning method for the situation when a balanced I/O load is critical, for instance when the number of I/O servers is large. File domains produced by this method are illustrated in Figure 2(d). Note that the number of aggregators is now reduced from six to five, co-prime to the number of I/O servers. In this method, the I/O servers together with the stripes of aggregate access region form a two-dimensional matrix. As the file system distributes file stripes to I/O servers in the matrix's row-major order, the transpose method assigns the stripes to the aggregators in the column-major order, like transposing a matrix. In Figure 2(d), the first three stripes in Server S0 are assigned to aggregator P0, followed by the fourth one to P1. The file domain for P1 continues to the second column, the stripes in Server S1. As a consequence, there is only one lock extent conflict per I/O server in this example. Unlike the group-cyclic method, the transpose method does not require any adjustment to the number of aggregators.
Some performance evaluation for these four file domain partitioning methods on Cray XT4 at ORNL is provided here.
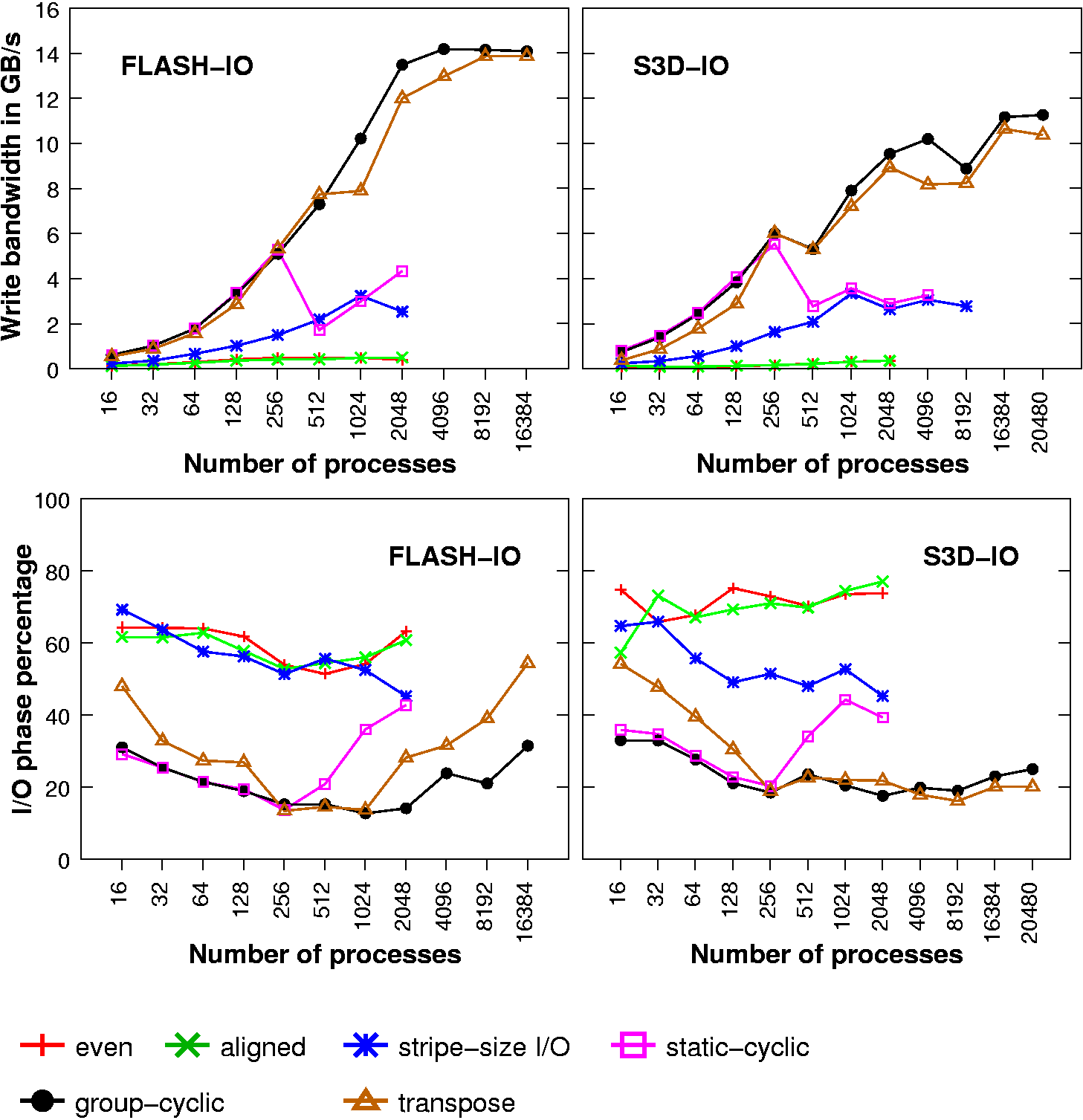{kind=link}
I/O Delegation:
I/O delegate software system uses a set of processes as gateway to the file system to carry out the I/O tasks for an application.
The goal in this approach is to execute
a caching layer within the I/O middleware
and the user application space. The IBM Blue Gene system adopts a similar strategy in its
I/O sub-system by physically adding a group of the I/O nodes sitting in between
the application nodes and file system servers. Compute nodes on a Blue Gene are organized into separate
processing sets, each of which contains one I/O node. I/O requests from the
compute nodes are accomplished via the I/O node. Thus, from the file system's
point of view, the I/O nodes are the actual I/O clients where the system's data
consistency semantics are enforced. This design off-loads the file access task
to the dedicated I/O nodes.
I/O delegate system is implemented as an
MPI-IO component that is linked and runs with the MPI applications. We believe
by placing the I/O system close to the applications and allowing the
applications to pass the high-level data access information, the I/O system has
more opportunity to provide better performance. In general, file system
interfaces do not provide sufficient functionality to pass high-level
application I/O information, such as data partitioning pattern and access
sequence nor can they make use of such information easily. For instance, file
systems can only see the starting file offset and requested length of
individual I/O requests, not knowing the sequence of requests could come from a
group of clients partitioning the same data objects. Incorporating the I/O
delegate system into MPI-IO allows access information to be passed from
applications to delegates that are critical for performance improvement. Some
of such access information has been identified and made use of in our delegate
system, such as the process groups sharing the files, process file view,
process synchronization, and user-specified I/O hints. Our delegate system
gathers such information and determines the I/O optimization for better
performance. The optimizations include file domain affiliation, file caching,
prefetching, request aggregation, and data redundancy.
The I/O delegate system architecture is illustrated in Figure 3. The delegate processes are created through the MPI dynamic process management facility, such as MPI_Comm_spawn(). Since the I/O delegates are also MPI processes, communication between the application processes and delegates is simply accomplished through MPI message passing functions with an MPI inter-communicator. One of the most important features of the I/O delegate system is it allows communication among delegates and enables their collaboration for further optimizations, such as collaborative caching, I/O aggregation, load balancing, and request alignment. Delegate system allows the application processes to transfer requests to any of the delegates if it results in a better performance.
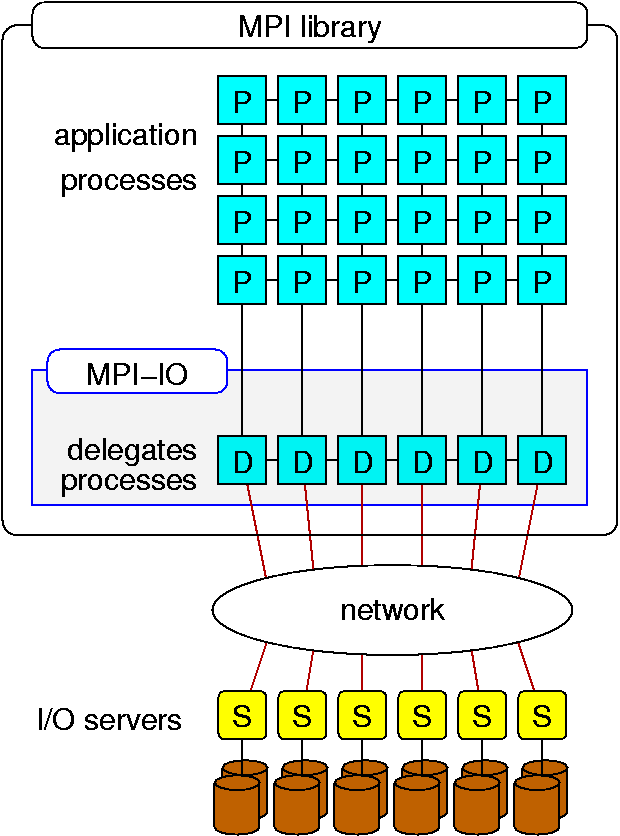
Figure 3. Software architecture of the proposed I/O delegate caching system
Based on this software I/O architecture we propose the following tasks:
- A distributed file caching mechanism
- Delegate fileview coordination
A distributed file caching mechanism:
Aiming to improve the non-contiguous, independent I/O performance, we will develop a distributed file caching mechanism in the I/O delegates. Small, non-contiguous I/O requests are commonly seen in production applications. ROMIO, a popular MPI-IO implementation developed at Argonne National Laboratory, uses a two-phase I/O strategy to reorganize these requests into large, contiguous ones. This strategy has demonstrated very successful for many I/O patterns. However, two-phase I/O is only applicable for collective I/O functions and collective I/O requires all processes open the shared file to synchronously participate in the I/O call, which may introduce process idle time. Without process synchronization, the MPI independent I/O functions have even less opportunity for better performance. Our design of using data caching at delegate side can reduce the performance gap between MPI independent and collective I/O. The idea is to replace the data reorganization among the application processes as currently done in the collective I/O with the data redistribution between application processes and the delegates. With the help of caching , the small, noncontiguous requests from independent I/O can be first buffered at the delegates. Once filled by different and successive independent requests, the cache pages will be flushed to the file system. This caching mechanism not only inherits the traditional data caching benefit of fast read-write operations for repeated access pattern, but also improves the performance for write-only operations which represent the majority I/O pattern in today's large-scale simulation applications.
Delegate Fileview Coordination:
One of the obstacles for high-performance parallel I/O is the overhead of data consistency control carried out by the underlying file systems . As the file system protects the data consistency through file locking, concurrent I/O operations could be serialized due to lock conflicts. Therefore, it is very important that the I/O requests are reorganized in our delegate system in a way that lock conflicts are minimized or completely eliminated. We will develop a method that assigns disjoint file regions to the I/O delegates such that the lock conflicts and overlapping accesses are resolved at the delegate system, instead of passing to the file system which would result in a much higher penalty. The partitioning will take into account the underlying file system striping configuration, such as the number of I/O servers that files are striped across. For example, for the Lustre file system, which implements a server-based locking protocol, we will arrange the I/O delegates to have a one-to-one or one-to-many mapping to the I/O servers. For the one-to-one mapping, each I/O delegate will only access one and the same server. This mapping requires that the file domain be partitioned exactly the same way as the file striping configuration of the file system. On many parallel file systems, such striping information can be obtained through the native file system APIs. The one-to-many mapping is when the number of I/O delegates is less than the I/O servers. We will adjust the number of delegates so that the number of servers is a multiple of the number of delegates, so that each delegate will access the same set of servers. From the I/O server's point of view, under both mappings, each server only serves one and the same delegate. This strategy has several advantages. For example, persistent pairing between servers and clients can reduce the number of lock acquisitions (to almost once in many cases), produce more effective data prefetching, and less cache coherence control overhead.
We conducted our experiments on production parallel machine Franklin, a Cray XT4 system at National Energy Research Scientific Computing Center. Native independent I/O when used with the I/O delegation architecture, scales up to 17 GB/sec on Franklin. I/O performance charts with two real I/O kernels and one benchmark are provided.
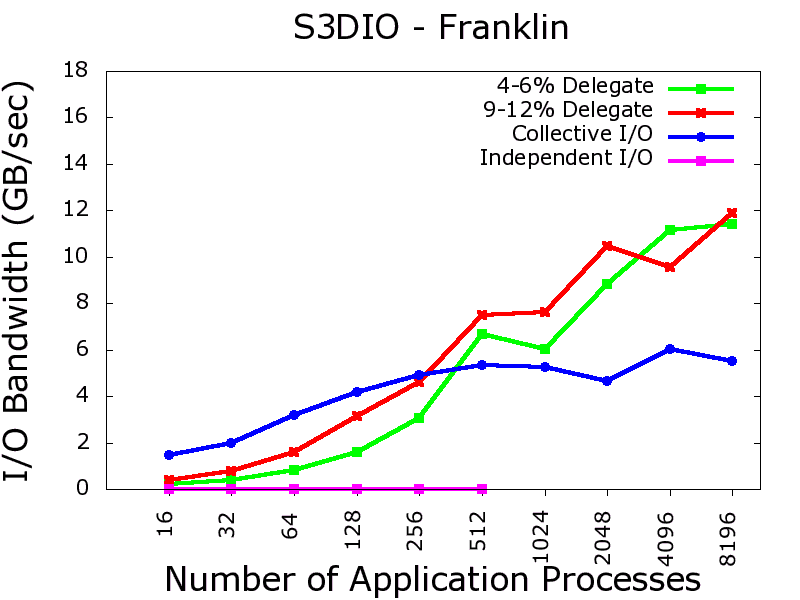
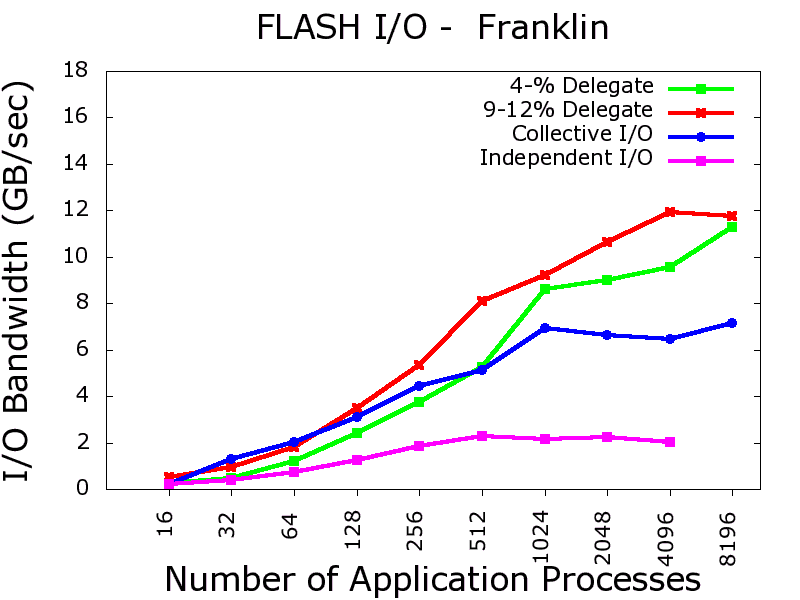
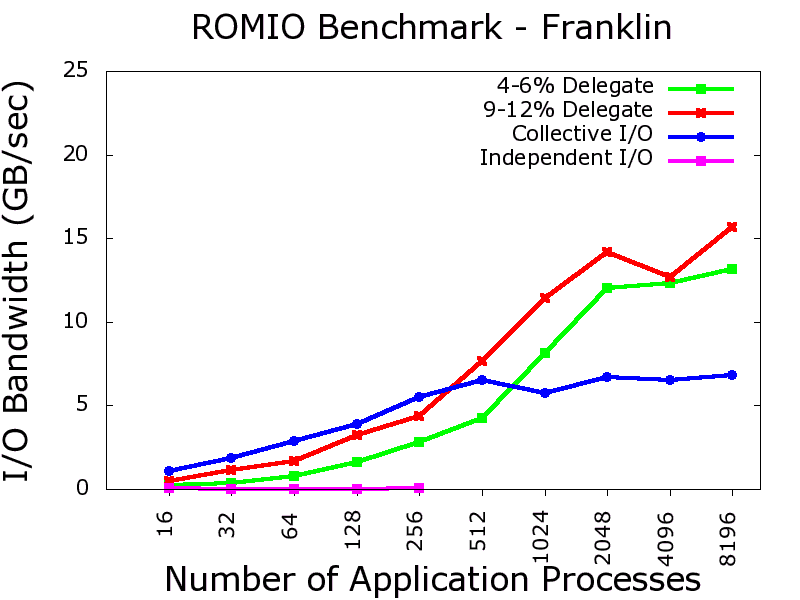
I/O performance comparison of independent I/O with I/O Delegation with the native (independent/collective I/O) cases. Click each figures for a bigger view.
Publications:
- Arifa Nisar, Wei-keng Liao and Alok Choudhary, Delegation-based I/O Mechanism for High Performance Computing Systems. IEEE Transactions on Parallel and Distributed Systems (To Appear TPDS 2011). [Paper] [Supplementary Document]
- Kui Gao, Wei-keng Liao, Arifa Nisar, Alok Choudhary, Robert Ross, and Robert Latham. Using Subfiling to Improve Programming Flexibility and Performance of Parallel Shared-file I/O. In the Proceedings of the International Conference on Parallel Processing, Vienna, Austria, September 2009.
- Wei keng Liao and Alok Choudhary. Dynamically adapting file domain partitioning methods for collective I/O based on underlying parallel file system locking protocols. In Proceedings of International Conference for High Performance Computing, Networking, Storage and Analysis (SC08), Austin, Texas, November 2008.
- Arifa Nisar, Wei keng Liao, and Alok Choudhary. Scaling parallel I/O performance through I/O delegate and caching system. In Proceedings of International Conference for High Performance Computing, Networking, Storage and Analysis (SC08), Austin, Texas, November 2008. (pdf)
- Robert Ross, Alok Choudhary, Garth Gibson, and Wei-keng Liao. Book Chapter: Parallel Data Storage and Access. In Scienti.c Data Management: Challenges, Technology, and Deployment, editors: Arie Shoshani and Doron Rotem, Chapman & Hall/CRC Computational Science Series, CRC Press, December 2009.
- Kui Gao, Wei-keng Liao, Alok Choudhary, Robert Ross, and Robert Latham. Combining I/O Operations for Multiple Array Variables in Parallel NetCDF. In the Proceedings of the Workshop on Interfaces and Architectures for Scienti.c Data Storage, held in conjunction with the the IEEE Cluster Conference, New Orleans, Louisiana, September 2009.
- Florin Isaila, Francisco Javier Garcia Blas, Jesus Carretero, Wei-keng Liao, and Alok Choudhary. A Scalable Message Passing Interface Implementation of an Ad-Hoc Parallel I/O System. International Journal of High Performance Computing Applications first published on October 5, 2009 as doi:10.1177/1094342009347890
- Alok Choudhary, Wei-keng Liao, Kui Gao, Arifa Nisar, Robert Ross, Rajeev Thakur, and Robert Latham. Scalable I/O and Analytics. In the Journal of Physics: Conference Series, Volume 180, Number 012048 (10 pp), August 2009.
- Jacqueline Chen, Alok Choudhary, Bronis de Supinski, Matthew DeVries, E. Hawkes, Scott Klasky, Wei-Keng Liao, Kwan-Liu Ma, John Mellor- Crummy, Norbert Podhorski, Ramanan Sankaran, Sameer Shende, Chun Sang Yoo. Terascale Direct Numerical Simulations of Turbulent Combustion Using S3D. In the Journal of Computational Science & Discovery, Volume 2, Number 015001, 2009.
- Florin Isaila, Francisco Javier Garcia Blas, Jesus Carretero, Wei-keng Liao, and Alok Choudhary. AHPIOS: An MPI-based Ad-hoc Parallel I/O System. In the Proceedings of 14th International Conference on Parallel and Distributed Systems, Melbourne, Victoria, Australia, December 2008.