
Sponsor:
This project is sponsored by DOE's Office of Science as part of the FAST-OS program.The award number is DE-FG02-08ER25848/A002.
Project Team Members:
Northwestern University
Argonne National Laboratory



Active Storage with Analytics Capabilities and I/O Runtime System for Petascale Systems
Introduction
Many of the important computational applications in science and engineering, sensor processing, and other disciplines have grown in complexity, scale, and the data set sizes that they produce, manipulate, and consume. Most of these applications have a data intensive component. For example, in applications such as climate modeling, combustion, and astrophysics simulations, data set sizes range between 100 TB and 10 PB, and the required compute performance is 100+ teraops. In other areas, data volumes grow as a result of aggregation. For example, proteomics and genomics applications may take several thousand 10-megabyte mass spectra of cell contents at thousands of time points and conditions, yielding a data rate of terabytes per day. Scientists and engineers require techniques, tools, and infrastructure to better understand this huge amount of data, in particular to effectively perform complex data analysis, statistical analysis, and knowledge discovery. As an example, scientists have been able to scale simulations to more than tens of thousands of processors (and for more than a million CPU-hours), but efficient I/O has been a problem. Indeed, in some cases, once the simulation is finished in a couple of days, several months are needed to organize, analyze, and understand the data. From a productivity perspective, this is a staggering number.
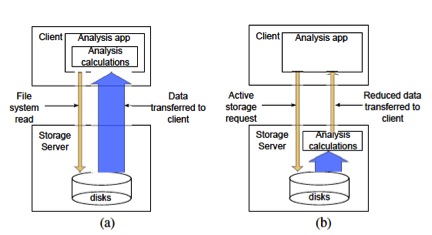
The performance of data analysis tasks that heavily rely on parallel file systems to perform their I/O is typically poor, mainly because of the cost of data transfer between the nodes that store the data and the nodes that perform the analysis. For applications that filter a huge amount of input data, the idea of an active storage system has been proposed to reduce the bandwidth requirement by moving the computation closer to the storage nodes. The concept of active storage is well suited for data-intensive applications; however, several limitations remain, especially in the context of parallel file systems. First, scientists and engineers use a variety of data analysis kernels including simple statistical operations, string pattern matching, visualization, and data mining kernels. Current parallel file systems lack a proper interface to utilize these various analysis kernels embedded in the storage side, thereby preventing wide deployment of active storage systems. Second, files in parallel file systems are typically striped across multiple servers and are often not perfectly aligned with respect to computational unit, making it difficult to process data locally in the general case. Third, most analysis tasks need to be able to broadcast and/or reduce the locally (partially) read or computed data with the data from other nodes. Unfortunately, current parallel file systems lack server-side communication primitives for aggregation and reduction.
The main contribution of this paper is an active storage system on parallel I/O software stacks. Our active storage system enables data analytic tasks within the context of parallel file systems through three key features:
We have implemented a prototype of our active storage system and demonstrate its benefits using four data analysis benchmarks. Our experimental results show that our proposed system improves the overall performance of all four benchmarks by 50.9% on average and that the compute-intensive portion of the k-means clustering kernel can be improved by 58.4% through GPU offloading when executed with a larger computational load. We also show that our scheme consistently outperforms the traditional storage model with a wide variety of input dataset sizes, number of nodes, and computational loads.
Publications:
- S. W. Son, S. Lang, P. Carns, R. Ross, R. Thakur, B. Ozisikyilmaz, P. Kumar, W. K. Liao, and A. Choudhary, Enabling Active Storage on Parallel I/O Software Stacks, In MSST 2010.
- A.Choudhary, W. K. Liao, K. Gao, A. Nisar, R. Ross, R. Thakur, and R. Latham. Scalable I/O and Analytics. In the Journal of Physics: Conference Series, Volume 180, Number 012048 (10 pp), August 2009
- B. Ozisikyilmaz, G. Memik, and A. Choudhary. Machine Learning Models to Predict Performance of Computer System Design Alternatives. In Proceedings of the International Conference on Parallel Processing (ICPP), September 2008.
- B. Ozisikyilmaz, G. Memik, and A. Choudhary. Efficient System Design Space Exploration Using Machine Learning Techniques. In Proceedings of The Design Automation Conference (DAC), June 2008.